3 Ways to Calculate R&D Value Creation
As a scientist by training (including 5 years as a full-time professor), I still find great joy in diving deep into research. Having transitioned to running a bootstrapped digital biology consultancy, it's become crucial to track how my time spent creates value for my business.
In fact, connecting R&D to value creation was an early lesson I received while working as a scientist at a synthetic biology company in 2012. It was no accident that company went on to score a billion-dollar IPO.
Although I eventually left in 2014 to do a 5-year postdoc at UCSD and then lead my computational biology lab as PI in Canada, that first lesson in the "real world" outside academia stuck with me.
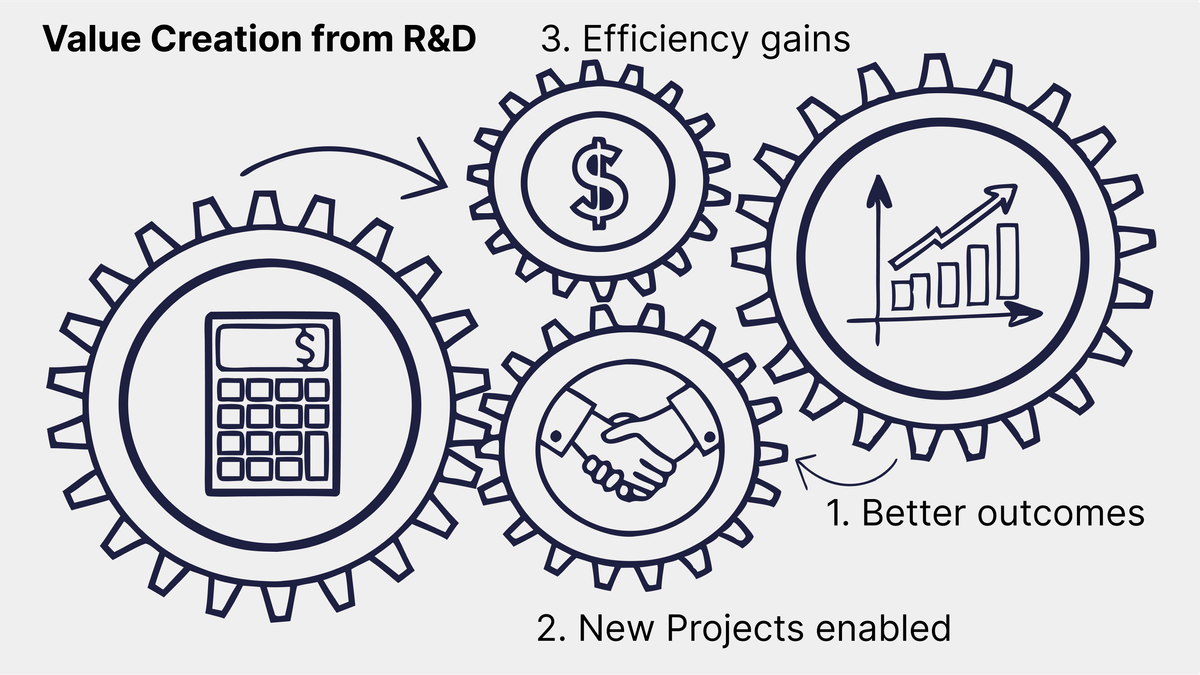
From my current bootstrapped startup perspective, there are 3 direct ways to trace value creation from R&D:
- New projects won directly due to R&D capabilities
- Added revenue from premium projects – either expanded scope or delivering greater benefits (higher return on client's investment)
- Cost reduction due to operational efficiencies, or capital expense reduction enabled through R&D
The associated value calculations are quite straightforward:
- New Project Value
Value = (Project Revenue) × (% Attributable to R&D)- Premium Project Value
Value = (Premium Rate - Standard Rate) × Project Count- Cost Reduction Value
Value = (Old Operational Cost - Reduced Operational Cost) x Operation HoursIn terms of prioritizing implementation, I'm personally pursuing: #2 ➔ #1 ➔ #3:
- #2 (Premium Project): Past projects revealed where the biggest benefits to clients were, and how my Service Packages can be improved to deliver even better outcomes
- #1 (New Project): having improved the offer, I can offer it to more clients
- #3 (Cost Reduction): having executed a greater number of projects, I identify points of friction in internal processes. Also in client workflows, which feeds in to #2 (improving the service package further).
How might this framework apply to your internal R&D?
Upgrade existing methods
This is probably the first place to start. While building brand new capabilities (e.g., an AI agent that can integrate all multi-modal data in house and completely automate workflows; or the latest multi-scale simulator) may seem attractive, those almost always take longer to build and require additional expertise that takes time and resources to learn.
Instead, there's likely a bottleneck you've identified in existing workflows that if alleviate will immediately increase productivity.
The good news is that few people have the nuanced understanding of the problem that you have--you're the best person to solve it. (Although getting help with a key missing piece of expertise isn't a bad idea if it can speed up execution 5-fold!)
Rapidly verify the benefit of new capabilities
Verify benefits rapidly using minimum viable products (MVP) or proof of concepts (PoC).
With AI tools like Perplexity, making a software PoC has never been faster – even if you need to use a package/library you've never used before.
And if you need stringent data privacy, you can use Ollama to run LLMs to generate code or interpret your data locally.
The key is to focus on verifying the benefit fast, and not get stuck optimizing the PoC before it's benefit has been validated. I feel that too many projects take months longer than they should because of this.
Resolve inefficiencies
This one should become apparent when there's an over-abundant volume of data to interpret, or jupyter notebooks that get repeatedly copied/pasted over and over again. There might be inefficiencies in how experiments are designed, or how data is deposited and processed. I won't dwell too much here as most of my experience (in industry and academia) have been in early-stage R&D and innovation.